基于Orekit的应用程序通常需要显式加载特定于应用程序的数据,除了使用数据上下文隐式加载的库本身的数据。这可能包括轨道和姿态星历文件、测量数据、地面站、参考GNSS解等。
一些最初为Orekit数据加载需求创建的机制,如数据存储和数据格式之间的分离,或者过滤,也可以用于应用程序数据。
最简单的重用所有机制的方法是使用默认配置和DataProvidersManager将应用程序数据和库数据合并,并将要读取的文件放置在与库相同的位置(例如主目录中的orekit-data文件夹)或者放置在应用程序特定位置,为此需要设置并注册一个DataProvider(通常是一个DirectoryCrawler)到DataProvidersManager中。
Orekit原生支持大量的数据格式。例如,闰秒信息可以从USNO提供的tai-utc.dat文件或IERS提供的UTC-TAI.history文件中加载。EOP数据可以从每周的Bulletin A、每月的Bulletin B、每年的EOPC04以及快速数据finals文件中检索。重力场可以从EGM、GRGS、ICGEM或SHM格式的文件中加载。
这种大量支持的格式是通过可扩展的低级数据加载架构实现的。使用这个架构,新的格式会定期添加到列表中,但用户也可以从中受益,并在他们的应用程序中为自己的格式添加支持。因此,可以在已经具有一些已建立的任务特定数据格式的系统中使用Orekit。
Orekit还支持在加载过程中对数据进行即时过滤。例如,如果数据以压缩或加密形式存储在磁盘上,并且在加载时应该解压缩或解密,可以使用过滤器进行过滤。Orekit中提供的预定义过滤器可以使用gzip(以.gz结尾的文件)、Unix压缩(以.Z结尾的文件)或Hatanaka方法(用于RINEX文件的特定模式,以.##d结尾的文件,其中##是RINEX 2文件的两位数年份,或以.crx结尾的文件,用于RINEX 3文件)来解压缩文件。
用户还可以从过滤器架构中受益,并在他们的应用程序中添加对自己过滤器的支持,例如解密敏感数据。
如果某种数据格式不被Orekit支持,用户可以设置一个专门的DataLoader实现。
这个类中最重要的方法是loadData方法。该方法的参数是一个已经打开的InputStream,可以使用常规的Java API从中读取数据。第二个参数是正在加载的数据文件的名称,它仅用于在文件损坏时生成有意义的错误消息给最终用户。该InputStream已经打开并已经通过了所有适用的过滤器。这意味着用户只需要关注解析本身,他们的自定义数据加载器将自动能够管理来自文件、网络、压缩或非压缩的数据,因为这些功能已经由数据提供者和数据过滤器处理好了。
将加载的数据提供给Orekit的方式在API中没有指定。实际上,这取决于数据类型。一种推荐的管理方式是为数据创建一个专门的容器类(在下面的图表中是ContainerWithNestedCustomParser),该类扩展了AbstractSelfFeedingLoader类,并在容器内部有一个实现了DataLoader的嵌套类Parser。
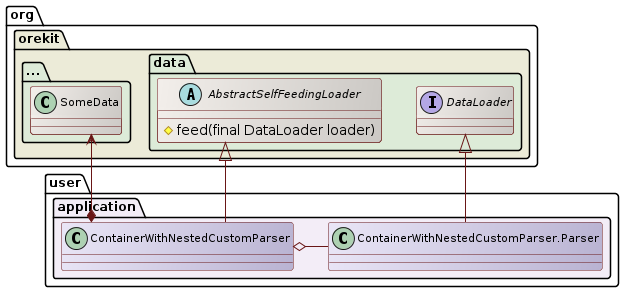
由于Parser嵌套在容器内部,它可以在解析过程中填充容器。为了让嵌套的解析器被填充,AbstractSelfFeedingLoader中的一个受保护的方法feed会被内部调用,参数是Parser,这个方法将触发配置的DataProvidersManager进行填充。用户可以查看BulletinAFilesLoader和YUMAParser的实现来了解它是如何工作的。
这可以用于加载Orekit已知的数据(如EOP),但只有文件格式未知,也可以用于加载应用程序数据。
然而,默认配置可能不适用于特定的应用数据需求,例如当只需要在包含许多类似文件的目录中加载一个特定的星历文件时,这取决于用户在列表中的选择。
在这种情况下,仍然可以通过配置应用程序特定的FiltersManager来依赖于较低级别的机制,例如过滤。在这种情况下,用户可以自己从头开始创建自己的解析器(或使用Orekit支持的标准格式的星历加载器之一),以这样的方式使用DataSource来指定要解析的字节或字符的来源,而不是直接使用File、InputStream或Reader。
