MySQL 8.3 Release Notes
组需要在每次更改时达成一致。 这适用于常规事务,但也适用于组成员更改和一些内部消息,以保持组的一致性。 达成一致需要组成员的多数同意。 当多数组成员丢失时,组无法推进并阻塞,因为它无法确保多数或仲裁。
仲裁可能会在多个非自愿故障时丢失,导致多数服务器突然从组中删除。 例如,在 5 服务器组中,如果 3 台服务器同时沉默,多数将被破坏,无法达成仲裁。 实际上,剩下的 2 台服务器无法确定其他 3 台服务器是否崩溃或是否网络分区将它们孤立,因此组无法自动重新配置。
另一方面,如果服务器自愿退出组,它们将指示组重新配置自己。 实际上,这意味着离开的服务器会告诉其他服务器它要离开。 这意味着其他成员可以正确地重新配置组,保持成员的一致性,并重新计算多数。 例如,在上述 5 服务器场景中,如果 3 台服务器同时离开,每台服务器都会警告组它要离开,然后成员将从 5 降低到 2,并在此过程中确保仲裁。
Note
仲裁的丢失本身是糟糕规划的结果。 计划组大小以预期的故障数量(无论是连续的、同时的还是零星的)。
对于单主模式的组,主服务器可能在网络分区时具有尚未在其他成员上出现的事务。 如果您考虑将主服务器从新组中排除,请注意这些事务可能会丢失。 带有额外事务的成员无法重新加入组,并尝试结果将导致错误,消息为 该成员具有比组中更多的已执行事务。 设置 group_replication_unreachable_majority_timeout 系统变量,以避免这种情况。
以下部分将解释,如果系统以这种方式分区,以至于服务器组自动无法达成仲裁。
性能架构表 replication_group_members 表示当前视图中每个服务器的状态,从这个服务器的角度来看。 大多数时间,系统不会出现分区,因此表格显示的信息在所有服务器组中是一致的。 但是,如果出现网络分区和仲裁损失,则表格将显示 UNREACHABLE 状态,表示无法联系的服务器。 这些信息是由 Group Replication 中的本地故障检测器导出的。
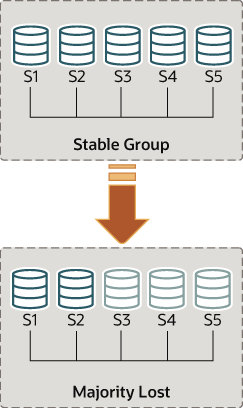
要理解这种网络分区,下一节将描述一个场景,其中最初有 5 台服务器正确工作,然后组中发生变化,仅剩 2 台服务器在线。 场景如图所示。
因此,让我们假设有一个组,包含以下 5 台服务器:
-
服务器 s1,成员标识符
199b2df7-4aaf-11e6-bb16-28b2bd168d07 -
服务器 s2,成员标识符
199bb88e-4aaf-11e6-babe-28b2bd168d07 -
服务器 s3,成员标识符
1999b9fb-4aaf-11e6-bb54-28b2bd168d07 -
服务器 s4,成员标识符
19ab72fc-4aaf-11e6-bb51-28b2bd168d07 -
服务器 s5,成员标识符
19b33846-4aaf-11e6-ba81-28b2bd168d07
最初,组运行良好,服务器之间愉快地通信。 您可以通过登录 s1 并查看其 replication_group_members 性能架构表来验证这一点。 例如:
mysql> SELECT MEMBER_ID,MEMBER_STATE, MEMBER_ROLE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+-------------+
| MEMBER_ID | MEMBER_STATE | MEMBER_ROLE |
+--------------------------------------+--------------+-------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | ONLINE | SECONDARY |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE | PRIMARY |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE | SECONDARY |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | ONLINE | SECONDARY |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | ONLINE | SECONDARY |
+--------------------------------------+--------------+-------------+然而,几秒钟后,服务器s3、s4和s5突然停止工作。几秒钟后,在s1上查看replication_group_members表时,发现它仍然在线,但其他一些成员不可达。实际上,如下所示,它们被标记为UNREACHABLE。此外,系统无法重新配置自己来更改成员资格,因为多数已经丢失。
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+表格显示s1现在处于一个组中,该组没有外部干预的进展,因为大多数服务器不可达。在这种特殊情况下,组成员列表需要被重置以允许系统继续,这将在本节中解释。或者,您也可以选择停止s1和s2上的组复制(或完全停止s1和s2),然后figuring out what happened with s3, s4 and s5,然后重新启动组复制(或服务器)。
组复制使您可以通过强制特定配置来重置组成员列表。例如,在上面的情况下,s1和s2是唯一在线的服务器,您可以选择强制包含只有s1和s2的成员配置。这需要检查s1和s2的一些信息,然后使用group_replication_force_members变量。
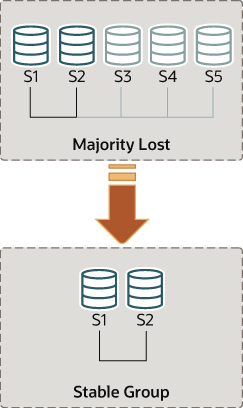
假设您回到只有s1和s2在线的情况下。服务器s3、s4和s5已经离开了组。要使s1和s2继续,您想强制包含只有s1和s2的成员配置。
Warning
该过程使用group_replication_force_members变量,应该被视为最后的手段。它 必须小心使用,仅用于超越quorum损失。如果misused,它可能会创建人工的split-brain场景或阻塞整个系统。
在强制新成员配置时,确保要排除的服务器确实已停止。在上面的场景中,如果s3、s4和s5并不是真正不可达,而是在线的,它们可能已经形成了自己的功能分区(它们是5中的3个,因此它们拥有多数)。在那种情况下,强制包含s1和s2的组成员列表可能会创建人工的split-brain情况。因此,在强制新成员配置之前,确保要排除的服务器确实已停止,如果它们没有停止,请在继续之前停止它们。
Warning
对于单主模式的组,主服务器可能在网络分区时拥有尚未在其他成员上出现的交易。如果您考虑排除主服务器,注意这些交易可能会丢失。拥有额外交易的成员无法重新加入组,尝试结果将出错,错误信息为该成员拥有比组中更多的已执行交易。设置group_replication_unreachable_majority_timeout系统变量,以避免这种情况。
回忆系统被阻塞,当前配置如下(根据s1上的本地故障检测器):
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+首先要做的是检查s1和s2的本地地址(组通信标识符)。登录s1和s2,获取该信息,如下所示。
mysql> SELECT @@group_replication_local_address;一旦您知道s1(127.0.0.1:10000)和s2(127.0.0.1:10001)的组通信地址,您可以使用该信息在其中一个服务器上注入新的成员配置,从而覆盖现有的配置,该配置已经丢失了quorum。在s1上执行该操作:
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";这将解除组阻塞,强制不同的配置。检查replication_group_members在s1和s2上,以验证组成员资格更改。首先在s1上。
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+然后在s2上。
mysql> SELECT * FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+在使用group_replication_force_members系统变量成功强制新组成员资格并解除组阻塞后,确保清空该系统变量。group_replication_force_members必须为空,以便发出START GROUP_REPLICATION语句。