MySQL 8.4 Release Notes
25.7.4 NDB 集群复制架构和表
NDB 集群中的复制使用了每个在集群中作为 SQL 节点的 MySQL 服务器实例上的 mysql 数据库中的专用表。这不论复制目标是单个服务器还是另一个集群都是如此。
以下是对`ndb_ binlog_index`和`ndb_apply_status`表格的描述。这些表格位于`mysql`数据库中。它们不应该由用户手动复制。通常情况下,用户不需要干预来创建或维护这两个表格,因为它们由NDB二进制日志注入线程自动维护。这确保了源mysqld进程与由NDB存储引擎执行的更改保持同步。NDB二进制日志注入线程直接从NDB存储引擎接收事件。这个注入线程负责捕获集群中的所有数据事件,并确保所有改变、插入或删除数据的事件都被记录在`ndb_binlog_index`表格中。副本I/O(接收者)线程将源的二进制日志中的事件转移到副本的中继日志。
必须手动创建ndb_replication表格。这张表格可以由用户更新,以便根据数据库或表格进行过滤。有关ndb_ replication 表格>的更多信息,请查看。ndb_ replication在 NDB 复制冲突检测和解决中也被用于冲突解决控制;请参阅冲突解决控制>。
尽管ndb_binlog_index和ndb_apply_status表格是自动创建并维护的,但在为 NDB 集群准备复制之前,建议检查这些表格的存在性和完整性。可以直接在源节点上查询mysql. ndb_binlog_index表格来查看记录在二进制日志中的事件数据。这也可以通过在源或副本 SQL 节点上的SHOW BINLOG EVENTS语句来实现。请参阅第 15.7.7.3 节,“SHOW BINLOG EVENTS 语句”。
您还可以从SHOW ENGINE NDB STATUS的输出中获得有用的信息。
Note
在对NDB表进行架构更改时,应用程序应等待MySQL客户端连接中执行的ALTER TABLE语句返回后再尝试使用表的更新定义。
ndb_apply_status用于记录源到副本的操作已经被复制。若在副本上不存在ndb_apply_status表,则ndb_restore将重新创建它。
与ndb_binlog_index不同,表中的数据不特定于任何一个SQL节点,因此ndb_apply_status可以使用NDBCLUSTER存储引擎,如下所示:
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH
) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;只有在副本上,ndb_apply_status表才会被填充;因此,在源端,这个表永远不会包含任何行,因此,不需要为其分配任何DataMemory。
由于该表是由源数据生成的,因此应该允许其复制;任何可能阻止副本更新 ndb_apply_status 的复制过滤规则或二进制日志过滤规则,或者阻止源写入二进制日志都可能导致集群间的复制不正常运行。关于这种过滤规则可能引起的问题,请参阅 NDB 集群之间的复制和二进制日志过滤规则。
可以删除这个表,但这不推荐。删除它会将所有 SQL 节点设置为只读模式;NDB 检测到该表已被删除,并重新创建它,之后就可以再次进行更新。丢弃并重新创建 ndb_apply_status 会在二进制日志中产生一个空事件;这个空事件会导致副本 SQL 节点停止从源节点应用更改,直到复制通道被重启。
0 在该表的 epoch 列中表示的是一个来自非 NDB 存储引擎的事务。
ndb_apply_status 用于记录哪些epoch的事务已经被复制并应用到一个从上游源复制的副本集群中。这项信息在 NDB 在线备份中捕获,但(设计之意)不会由 ndb_restore 恢复。在某些情况下,为了在新部署中使用,这项信息可以通过在 ndb_restore 命令中使用 --with-apply-status 选项来恢复。有关该选项的更多信息,请参阅其描述。
NDB 集群复制使用 ndb_binlog_index 表来存储二进制日志的索引数据。由于这个表是每个 MySQL 服务器本地的,不参与集群,它使用 InnoDB 存储引擎。这意味着它必须在每个参与源集群的 mysqld 上单独创建。(二进制日志本身包含了所有集群中 MySQL 服务器的更新。)这个表定义如下:
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Note
如果您正在从旧版本升级,执行MySQL升级程序,并确保系统表被升级。在启动MySQL服务器时使用--upgrade=FORCE选项来升级系统表。系统表的升级会导致对该表执行一个ALTER TABLE ... ENGINE=INNODB语句。对于这个表继续使用MyISAM存储引擎以保持向后兼容性。
ndb_-binlog_index在转换为InnoDB后可能需要额外的磁盘空间。如果这成为问题,您可能可以通过为该表使用一个InnoDB数据表空间、更改其ROW_FORMAT到COMPRESSED,或者两者兼而有之来节省空间。有关更多信息,请参阅第15.1.21节,“CREATE TABLESPACE Statement”、第15.1.20节,“CREATE TABLE Statement”以及第17.6.3节,“Tablespaces”。
`ndb_binlog_index` 表的大小取决于每个二进制日志文件的epochs数量以及二进制日志文件的总数。通常,每个二进制日志文件中的epochs数量取决于每个epoch生成的二进制日志量和二进制日志文件的大小,较小的epochs会导致更多的epochs被写入同一个文件中。你应该注意到,即使`--ndb-log-empty-epochs`选项设置为`OFF`,空的epochs也会产生对`ndb_binlog_index`表的插入。这意味着每个文件中的条目数量取决于该文件使用的时间长度;这种关系可以用以下公式表示:
[number of epochs per file] = [time spent per file] / TimeBetweenEpochs一个繁忙的NDB集群会定期向二进制日志写入,并且相对较安静的集群更快地轮换二进制日志文件。这意味着一个使用`--ndb-log-empty-epochs=ON`的“安静”NDB集群实际上可能会在同一个文件中有比活动较多的集群更多的`ndb_binlog_index`行。
当mysqld使用--ndb-log-orig选项启动时,orig_server_id和orig_epoch列分别存储事件起源服务器的ID和事件发生的epoch,这对于在多源NDB集群中进行复制设置非常有用。用于在多源设置中找到副本上最高应用的epoch最近的二进制日志位置的SELECT语句(参见第25.7.10节,“NDB集群复制:双向和环形复制”)使用了这两个列,但它们没有索引。这可能导致在尝试故障转移时性能问题,因为查询必须进行表扫描,尤其是在源服务器使用--ndb-log-empty-epochs=ON时。通过为这些列添加索引,您可以提高多源故障转移时间,如下所示:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);添加此索引对于从单一源复制到单一副本的场景无益,因为用于获取二进制日志位置的查询在这种情况下不使用orig_server_id或orig_epoch。
查看第25.7.8节“实现故障转移与NDB集群复制”以获取有关使用next_ position和next_file列的更多信息。
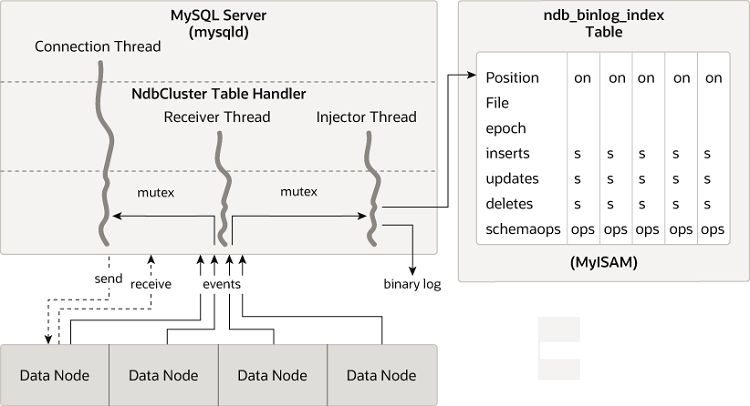
以下图表显示了NDB集群复制源服务器、其二进制日志注入线程以及mysql.ndb_binlog_index表之间的关系。
表ndb_ replication用于控制二进制日志记录和冲突解决,并且是基于表的。该表中的每一行对应于一个被复制的表,确定如何记录该表的更改,以及如果指定了冲突解决函数,则确定如何解决该表的冲突。
与ndb_ apply_status和ndb_ replication表不同,表ndb_ replication必须手动创建,使用以下SQL语句:
CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB
PARTITION BY KEY(db,table_name);该表的列如下所示,其中包含描述:
-
db列包含要复制的表的数据库名称。
您可以在数据库名称中使用任意数量的通配符
*和%。(请参阅匹配通配符,稍后在本节中。) -
table_name列要复制的表格名称。
表格名称可以包含任意或两者中的通配符
_和%。请参阅后文中关于匹配通配符的部分。 -
server_id列MySQL 实例(SQL 节点)的唯一服务器 ID,其中表格驻留。
0在这列中起作用,就像是一个通配符的等价形式%,能够匹配任何服务器 ID。请参阅匹配通配符后文部分。 -
binlog_type列要使用的二进制日志类型。请参阅文本中的值和描述。
-
conflict_fn列要应用的冲突解决函数;其中之一是NDB$OLD(),NDB$MAX(),NDB$MAX_DELETE_WIN(),NDB$EPOCH(),NDB$EPOCH_TRANS(),NDB$EPOCH2(),NDB$EPOCH2_TRANS(),NDB$MAX_INS(),或NDB$MAX_DEL_WIN_INS();
NULL表示对于该表不使用冲突解决。查看Conflict Resolution Functions,以获取有关这些函数及其在 NDB 复制中使用的冲突解决功能的更多信息。
一些冲突解决函数(
NDB$OLD(),NDB$EPOCH(),NDB$EPOCH_TRANS())需要使用一个或多个用户创建的异常表。请参阅冲突解决异常表。
为了在NDB复制中启用冲突解决,它必须在SQL节点或节点上创建并填充该表,用于控制信息。在源、副本或两者之间进行冲突解决时,这可能是源服务器、副本服务器或两者。简单的源-副本设置中,如果数据也可以在副本上本地更改,这通常是副本。在更复杂的复制方案中,如双向复制,这通常涉及所有参与的源服务器。请参阅第25.7.12节,“NDB集群复制冲突解决”,获取更多信息。
`ndb_replication`表允许在冲突解决之外对二进制日志进行表级别控制。在这种情况下,conflict_fn被指定为NULL,而剩余的列值用于控制给定表或一组表的二进制日志。通过设置`binlog_type`列的适当值,您可以使给定表或表的二进制日志使用所需的二进制日志格式,或完全禁用二进制日志。该列可能的值及其描述如下表所示:
表格25.42 binlog_type值及其描述
| Value | Description |
|---|---|
| 0 | 使用服务器默认设置 |
| 1 | 不在二进制日志中记录此表(与sql_log_bin = 0相同,但仅适用于指定的表) |
| 2 | 只记录更新的属性;将这些作为WRITE_ROW事件记录 |
| 3 | 记录完整行,即使未被更新(MySQL服务器默认行为) |
| 6 | 即使值未改变,也使用更新后的属性 |
| 7 | 记录完整行,即使没有值被更改;将更新作为UPDATE_ROW事件记录 |
| 8 | 将更新作为UPDATE_ROW记录;只在before image中记录主键列,在after image中只记录更新的列(与--ndb-log-update-minimal相同,但仅适用于指定的表) |
| 9 | 将更新作为UPDATE_ROW记录;在before image中只记录主键列,在after image中记录除主键外的所有列 |
Note
binlog_type值4和5不使用,因此省略了上述表格以及下一个表格中的显示。
有几个 binlog_ type 的值是等价于 MySQL 服务器 (mysqld) 的不同组合的日志选项,包括 --ndb- log- updated-only、--ndb-log-update-as-write 和 --ndb-log-update-minimal,如表格所示:
表 25.43 binlog_type 值与 NDB 日志选项的等价组合
| Value | --ndb-log-updated-only Value |
--ndb-log-update-as-write Value |
--ndb-log-update-minimal Value |
|---|---|---|---|
| 0 | — | — | — |
| 1 | — | — | — |
| 2 | ON | ON | OFF |
| 3 | OFF | ON | OFF |
| 6 | ON | OFF | OFF |
| 7 | OFF | OFF | OFF |
| 8 | ON | OFF | ON |
| 9 | OFF | OFF | ON |
二进制日志可以根据不同的表格格式进行设置,通过在 ndb_Replication 表中插入行来实现,这需要使用适当的 db、table_name 和 binlog_type 列值。前面表格中的内部整数值应该在设置二进制日志格式时使用。以下两个语句分别将二进制日志设置为对表 test.a 的全行记录 (值 3) 和对表 test.b 的更新记录 (值 2) 进行记录:
# Table test.a: Log full rows
INSERT INTO mysql.ndb_replication VALUES("test", "a", 0, 3, NULL);
# Table test.b: log updates only
INSERT INTO mysql.ndb_replication VALUES("test", "b", 0, 2, NULL);要禁用对一或多个表的日志记录,请使用 1 作为 binlog_type,如下所示:
# Disable binary logging for table test.t1
INSERT INTO mysql.ndb_replication VALUES("test", "t1", 0, 1, NULL);
# Disable binary logging for any table in 'test' whose name begins with 't'
INSERT INTO mysql.ndb_replication VALUES("test", "t%", 0, 1, NULL);对某个表禁用日志记录等同于设置 sql_log_bin = 0,但它是针对单个或多个表进行的。若一个 SQL 节点对于某个表不执行二进制日志记录,它将不会接收到该表的行变化事件。这意味着它并不是丢弃了一些更改,而是没有订阅这些更改。
禁用日志记录有多种原因,包括以下几点:
-
不发送更改通常会节省网络带宽、缓冲区和 CPU 资源的使用。
-
对于频繁更新但价值不高的表(如会话数据),禁用日志记录是一个好选择,因为这些数据在集群完全失败时可能并不重要。
-
通过会话变量 (或
sql_log_bin) 和应用程序代码,还可以选择性地记录 (或不记录) 特定的 SQL 语句或 SQL 语句类型;例如,在某些情况下,可能希望在一或多个表上禁用 DDL 语句的记录。 -
将复制流分割成两个(或更多)二进制日志可以用于性能提升、需要将不同数据库复制到不同的位置、对不同数据库使用不同的二进制日志类型等原因。
使用通配符匹配. 为了避免为每种组合的数据库、表和SQL节点在复制设置中插入一行到 ndb_Replication 表中,NDB 支持在该表的 db、table_name 和 server_id 列上使用通配符匹配。数据库和表名用于分别的 db 和 table_name 可以包含以下任一或两者的通配符:
-
_(下划线字符):匹配零个或多个字符 -
%(百分比符号):匹配单个字符
(这些是MySQL LIKE 运算符支持的相同通配符。)
server_id 列支持 0 作为通配符,相当于 _(匹配任何内容)。这是之前展示的例子中使用的。
在 ndb_replication 表中,一个给定的行可以使用通配符来匹配数据库名称、表名和服务器ID中的任意组合。表中如果有多个潜在的匹配项,那么会选择最佳匹配项,这根据以下表格决定,其中 W 表示通配符匹配,E 表示精确匹配,而质量值越高,匹配越好:
表25.44 通配符和精确匹配组合在 mysql.ndb_replication 表中的权重
db |
table_name |
server_id |
Quality |
|---|---|---|---|
| W | W | W | 1 |
| W | W | E | 2 |
| W | E | W | 3 |
| W | E | E | 4 |
| E | W | W | 5 |
| E | W | E | 6 |
| E | E | W | 7 |
| E | E | E | 8 |
因此,数据库名称、表名和服务器ID的精确匹配被认为是最佳(最强)的,而在所有三个列上都进行通配符匹配则被认为是最弱(最差)的。只有匹配的强度会影响选择哪条规则时的决定;表中的行顺序对此决策没有任何影响。
记录完整行或部分行。 有两种基本的方法来记录行,取决于--ndb-log-updated-only选项对于mysqld的设置:
-
记录完整行(选项设置为
ON) -
仅记录更新过的列数据—that is,列数据,其值已被设置,即使该值未实际更改。这是默认行为(选项设置为
OFF)。
通常,只记录更新过的列数据就足够了,并且效率更高;但是,如果您需要记录完整行,您可以通过将--ndb-log-updated-only设置为0或OFF来实现。
以更新的形式记录更改数据。 MySQL服务器的--ndb-log-update-as-write选项的设置决定了是否在记录时使用或不使用“before”图像。
由于MySQL Server在更新和删除操作的冲突解决中使用了更新处理器,因此必须控制复制源的日志记录,以确保更新被视为更新而不是写入;也就是说,更新应该被视为现有行的更改,而不应该被视为新行的写入,即使这些更新会替换现有的行。
这个选项默认是打开的;换句话说,更新默认被视为写入。也就是说,更新默认在二进制日志中以write_row事件的形式记录,而不是以update_row事件的形式。
要禁用这个选项,可以使用命令行参数--ndb-log-update-as-write=0或--ndb-log-update-as-write=OFF启动源mysqld。您必须在从NDB表复制到使用不同存储引擎的表时这样做;请参阅从NDB复制到其他存储引擎和从NDB复制到非事务性存储引擎,获取更多信息。
Important
为了使用 NDB$MAX_INS() 或 NDB$MAX_DEL_WIN_INS() 进行插入冲突解决,一个 SQL 节点(即一个 mysqld 进程)可以在源集群中记录行更新作为 WRITE_ROW 事件,前提是启用了 --ndb-log-update-as-write 选项,以实现幂等性并优化大小。这两种算法都可以工作,因为它们都会将 WRITE_ROW 事件映射为插入或更新,取决于行是否已经存在,并且所需的元数据(时间戳列的“after”图像)在 “WRITE_ROW” 事件中就绪。