MySQL 8.3 Release Notes
在 NDB 集群中,复制使用了 MySQL 服务器实例上的几个专用表,这些实例充当集群的 SQL 节点,无论是被复制的集群还是副本。
在 mysql 数据库中创建了 ndb_binlog_index 和 ndb_apply_status 表。这些表不应该被用户明确复制。通常不需要用户干预来创建或维护这些表,因为它们都是由 NDB 二进制日志(binlog)injector 线程维护的。
用户必须手动创建 ndb_replication 表。该表可以由用户更新,以便根据数据库或表进行过滤。请参阅 ndb_replication 表,以获取更多信息。ndb_replication 也用于 NDB 复制冲突检测和解决冲突控制;请参阅 冲突解决控制。
尽管 ndb_binlog_index 和 ndb_apply_status 是自动创建和维护的,但是在准备 NDB 集群复制之前,检查这些表的存在和完整性是一个良好的做法。在源上可以通过查询 mysql.ndb_binlog_index 表直接查看二进制日志中的事件数据。也可以使用 SHOW BINLOG EVENTS 语句在源或副本 SQL 节点上执行。(请参阅 第 15.7.7.3 节,“SHOW BINLOG EVENTS 语句”。)
您也可以从 SHOW ENGINE NDB STATUS 的输出中获取有用的信息。
Note
在对 NDB 表进行模式更改时,应用程序应该等待 ALTER TABLE 语句在发出语句的 MySQL 客户端连接中返回,然后才能尝试使用更新后的表定义。
ndb_apply_status 表用于记录从源到副本的复制操作。如果副本上不存在 ndb_apply_status 表,ndb_restore 将重新创建它。
与 ndb_binlog_index 不同的是,这个表中的数据不特定于集群中的任何一个 SQL 节点,因此 ndb_apply_status 可以使用 NDBCLUSTER 存储引擎,如下所示:
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH
) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;该 ndb_apply_status 表仅在副本上填充,这意味着,在源上,该表从不包含任何行;因此,在源上不需要为 ndb_apply_status 分配任何 DataMemory。
因为该表来自源上的数据,因此应该允许其复制;任何复制过滤或二进制日志过滤规则意外地阻止副本更新 ndb_apply_status,或阻止源写入二进制日志,可能会阻止集群之间的复制正常工作。有关这些过滤规则可能引发的问题的更多信息,请参阅 Replication and binary log filtering rules with replication between NDB Clusters。
可以删除该表,但这不建议。删除它将使所有 SQL 节点变为只读模式:NDB 将检测到该表已被删除,并重新创建它,之后可以再次执行更新。删除并重新创建 ndb_apply_status 将在二进制日志中创建一个间隙事件;该间隙事件将导致副本 SQL 节点停止从源应用更改,直到复制通道被重新启动。
0 在该表的 epoch 列中表示来自非 NDB 存储引擎的事务。
ndb_apply_status 用于记录哪些 epoch 事务已经被复制并应用于副本集群来自上游源的信息。该信息将被捕获在 NDB 在线备份中,但(按照设计)它不会被 ndb_restore 还原。在某些情况下,可以恢复该信息以供新设置使用;可以通过使用 ndb_restore 选项 --with-apply-status 来实现。请参阅选项的描述以获取更多信息。
NDB 集群复制使用 ndb_binlog_index 表来存储二进制日志的索引数据。由于该表是每个 MySQL 服务器的本地表,不参与集群,因此它使用 InnoDB 存储引擎。这意味着它必须在每个参与源集群的 mysqld 上单独创建。(二进制日志本身包含来自集群中所有 MySQL 服务器的更新。)该表定义如下:
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Note
如果您来自旧版本(NDB 7.5.2 之前),请执行 MySQL 升级过程,并确保系统表通过启动 MySQL 服务器时使用 --upgrade=FORCE 选项升级。系统表升级将导致对该表执行 ALTER TABLE ... ENGINE=INNODB 语句。使用 MyISAM 存储引擎继续支持该表,以便向后兼容。
ndb_binlog_index 可能需要在将其转换为 InnoDB 后增加磁盘空间。如果这成为问题,可以通过使用 InnoDB 表空间、将其 ROW_FORMAT 更改为 COMPRESSED 或两者来节省空间。有关更多信息,请参阅 Section 15.1.21, “CREATE TABLESPACE Statement” 和 Section 15.1.20, “CREATE TABLE Statement”,以及 Section 17.6.3, “Tablespaces”。
该 ndb_binlog_index 表的大小取决于每个二进制日志文件中的epochs数和二进制日志文件数。每个二进制日志文件中的epochs数通常取决于每个epochs生成的二进制日志量和二进制日志文件的大小,小的epochs将导致每个文件中的epochs数更多。你应该注意,即使 --ndb-log-empty-epochs 选项设置为 OFF,空epochs仍将在 ndb_binlog_index 表中生成插入,即使该选项设置为 OFF,文件中的条目数取决于文件使用的时间长度;这种关系可以用以下公式表示:
[number of epochs per file] = [time spent per file] / TimeBetweenEpochs繁忙的 NDB 集群会定期写入二进制日志,并且比安静的集群更频繁地旋转二进制日志文件。这意味着,一个安静的 NDB 集群,使用 --ndb-log-empty-epochs=ON,可能比一个繁忙的集群拥有更多的 ndb_binlog_index 行数。
当 mysqld 使用 --ndb-log-orig 选项启动时,orig_server_id 和 orig_epoch 列分别存储事件在原始服务器上的 ID 和事件发生的epochs,这在 NDB 集群复制设置中使用多个源时非常有用。SELECT 语句用于查找多源设置中副本上的最高应用 epochs 的最近二进制日志位置(见 第 25.7.10 节,“NDB 集群复制:双向和循环复制”),使用这两个未索引的列,这可能会导致故障转移时的性能问题,因为查询必须执行表扫描,特别是在源服务器上使用 --ndb-log-empty-epochs=ON 时。你可以通过添加这两个列的索引来改善多源故障转移时间,如下所示:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);添加该索引在从单个源复制到单个副本时没有任何益处,因为在这种情况下,用于获取二进制日志位置的查询不使用 orig_server_id 或 orig_epoch。
请参阅 第 25.7.8 节,“使用 NDB 集群复制实现故障转移”,以获取有关使用 next_position 和 next_file 列的更多信息。
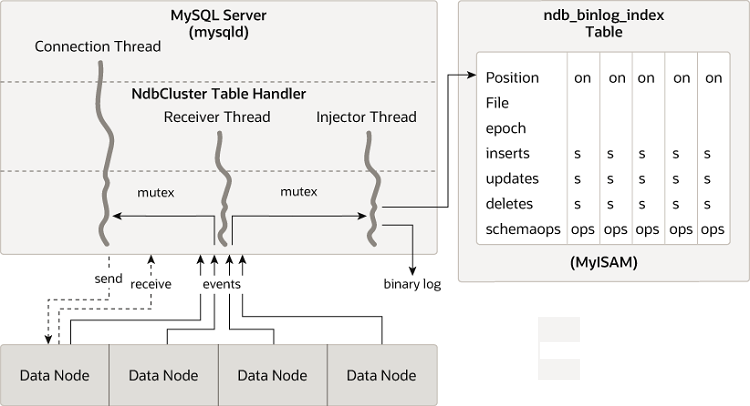
以下图表显示了 NDB 集群复制源服务器、其二进制日志注入线程和 mysql.ndb_binlog_index 表之间的关系。
该 ndb_replication 表用于控制二进制日志记录和冲突解决,并在每个表的基础上进行操作。该表中的每一行对应一个被复制的表,确定如何记录该表的更改,并且如果指定了冲突解决函数,则确定如何解决该表的冲突。
与 ndb_apply_status 和 ndb_replication 表不同,ndb_replication 表必须手动创建,使用以下 SQL 语句:
CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB
PARTITION BY KEY(db,table_name);该表的列列举如下,带有描述:
-
db列要复制的表所在的数据库的名称。
你可以在数据库名称中使用通配符
_和%。(见 使用通配符,本节后面。) -
table_name列要复制的表的名称。
表名称可以包含通配符
_和%。见 使用通配符,本节后面。 -
server_id列MySQL 实例(SQL 节点)中的唯一服务器 ID,其中该表驻留。
0在该列中充当通配符,相当于%,并匹配任何服务器 ID。(参见 使用通配符匹配,本节后面。) -
binlog_type列要使用的二进制日志记录类型。请参阅文本以获取值和描述。
-
conflict_fn列要应用的冲突解决函数;可以是 NDB$OLD()、NDB$MAX()、NDB$MAX_DELETE_WIN()、NDB$EPOCH()、NDB$EPOCH_TRANS()、NDB$EPOCH2()、NDB$EPOCH2_TRANS()、NDB$MAX_INS() 或 NDB$MAX_DEL_WIN_INS();
NULL表示不使用冲突解决函数来解决该表的冲突。请参阅 冲突解决函数,以获取这些函数的更多信息及其在 NDB 复制冲突解决中的使用。
一些冲突解决函数 (
NDB$OLD()、NDB$EPOCH()、NDB$EPOCH_TRANS()) 需要使用一个或多个用户创建的异常表。请参阅 冲突解决异常表。
要启用 NDB 复制冲突解决,需要在 SQL 节点或节点上创建和填充该表,以便控制信息在源或副本服务器上解决冲突。根据冲突解决类型和方法,可能是源、副本或所有参与的服务器。在简单的源副本设置中,数据也可以在副本上本地更改,这通常是副本。在更复杂的复制方案中,例如双向复制,这通常是所有参与的源服务器。请参阅 第 25.7.12 节,“NDB 集群复制冲突解决”,以获取更多信息。
该 ndb_replication 表允许在冲突解决范围外对二进制日志记录进行表级控制,在这种情况下 conflict_fn 指定为 NULL,而剩余的列值用于控制二进制日志记录的给定表或匹配通配符表达式的表。通过设置 binlog_type 列的适当值,可以使给定表或表的二进制日志记录使用所需的二进制日志格式,或者完全禁用二进制日志记录。可能的值和描述如下表所示:
表 25.70 binlog_type 值,带值和描述
| Value | Description |
|---|---|
| 0 | 使用服务器默认值 |
| 1 | 不要在二进制日志中记录该表(与 sql_log_bin = 0 相同,但仅适用于一个或多个指定的表) |
| 2 | 仅记录更新的属性;将其记录为 WRITE_ROW 事件 |
| 3 | 记录完整的行,即使未更新(MySQL 服务器默认行为) |
| 6 | 使用更新的属性,即使值未更改 |
| 7 | 记录完整的行,即使未更改;将更新记录为 UPDATE_ROW 事件 |
| 8 | 记录更新为 UPDATE_ROW;在 before 图像中仅记录主键列,在 after 图像中仅记录更新的列(与 --ndb-log-update-minimal 相同,但仅适用于一个或多个指定的表) |
| 9 | 记录更新为 UPDATE_ROW;在 before 图像中仅记录主键列,在 after 图像中记录所有非主键列 |
Note
binlog_type 值 4 和 5 未使用,因此从上表中省略,以及从下表中省略。
多个 binlog_type 值等同于各种组合的 mysqld 日志选项 --ndb-log-updated-only, --ndb-log-update-as-write, 和 --ndb-log-update-minimal, 如下表所示:
表 25.71 binlog_type 值与等效的 NDB 日志选项组合
| Value | --ndb-log-updated-only Value |
--ndb-log-update-as-write Value |
--ndb-log-update-minimal Value |
|---|---|---|---|
| 0 | -- | -- | -- |
| 1 | -- | -- | -- |
| 2 | ON | ON | OFF |
| 3 | OFF | ON | OFF |
| 6 | ON | OFF | OFF |
| 7 | OFF | OFF | OFF |
| 8 | ON | OFF | ON |
| 9 | OFF | OFF | ON |
二进制日志记录可以根据不同的表设置不同的格式,方法是将行插入 ndb_replication 表中,使用适当的 db、table_name 和 binlog_type 列值。前表中的内部整数值应在设置二进制日志格式时使用。以下两个语句将二进制日志记录设置为完整行日志(值 3)对于表 test.a,并将其设置为仅更新日志(值 2)对于表 test.b:
# Table test.a: Log full rows
INSERT INTO mysql.ndb_replication VALUES("test", "a", 0, 3, NULL);
# Table test.b: log updates only
INSERT INTO mysql.ndb_replication VALUES("test", "b", 0, 2, NULL);要禁用一个或多个表的日志记录,使用 1 作为 binlog_type,如下所示:
# Disable binary logging for table test.t1
INSERT INTO mysql.ndb_replication VALUES("test", "t1", 0, 1, NULL);
# Disable binary logging for any table in 'test' whose name begins with 't'
INSERT INTO mysql.ndb_replication VALUES("test", "t%", 0, 1, NULL);禁用某个表的日志记录等同于设置 sql_log_bin = 0,只是它适用于一个或多个表。 如果 SQL 节点不执行某个表的二进制日志记录,它将不会收到该表的行更改事件。这意味着它不订阅这些更改,而不是接收所有更改并丢弃一些。
禁用日志记录可能有多种原因,包括以下几点:
-
不将更改发送到网络通常可以节省带宽、缓冲区和 CPU 资源。
-
对于非常频繁更新但价值不高的表,禁用日志记录可能是合适的,例如会话数据,这些数据在集群完全失败时可能不太重要。
-
使用会话变量(或
sql_log_bin)和应用程序代码,也可以记录(或不记录)某些 SQL 语句或 SQL 语句类型;例如,在某些情况下可能不想记录 DDL 语句到一个或多个表。 -
将复制流分割成两个(或多个)二进制日志可以出于性能、需要将不同数据库复制到不同地方、使用不同二进制日志类型的数据库等原因。
使用通配符匹配. 为了不需要在 ndb_replication 表中插入每个组合的数据库、表和 SQL 节点的行,NDB 支持在该表的 db、table_name 和 server_id 列上使用通配符匹配。数据库和表名在 db 和 table_name 中可以包含以下通配符:
-
_(下划线字符):匹配零个或多个字符 -
%(百分号):匹配单个字符
(这些是 MySQL LIKE 运算符支持的同样的通配符。)
该 server_id 列支持 0 作为通配符,相当于 _(匹配任何内容)。这在前面的示例中使用。
给定的 ndb_replication 表行可以使用通配符来匹配数据库名称、表名称和服务器 ID 的任何组合。其中有多个潜在匹配项时,选择最佳匹配项,根据以下表所示,其中 W 代表通配符匹配,E 代表精确匹配,而 Quality 列中的值越大,匹配项越好:
表 25.72 NDB 复制表中的通配符和精确匹配权重
db |
table_name |
server_id |
Quality |
|---|---|---|---|
| W | W | W | 1 |
| W | W | E | 2 |
| W | E | W | 3 |
| W | E | E | 4 |
| E | W | W | 5 |
| E | W | E | 6 |
| E | E | W | 7 |
| E | E | E | 8 |
因此,在数据库名称、表名称和服务器 ID 之间进行精确匹配被认为是最强的,而在所有三个列上进行通配符匹配是最弱的。只有匹配的强度被考虑在选择哪个规则应用时;表中的行顺序对此决定没有影响。
记录完整或部分行。 有两个基本方法来记录行,如 --ndb-log-updated-only 选项所确定的那样,用于 mysqld:
-
记录完整行(选项设置为
ON) -
仅记录已更新的列数据,即其值已被设置的列数据,无论其值是否实际更改。这是默认行为(选项设置为
OFF)。
通常来说,仅记录更新的列就足够了,并且更高效;但是,如果您需要记录完整的行,可以通过将 --ndb-log-updated-only 设置为 0 或 OFF 来实现。
将更改记录为更新。 MySQL 服务器的 --ndb-log-update-as-write 选项确定是否在记录中包含“before”图像。
因为更新和删除操作的冲突解决是在 MySQL 服务器的更新处理程序中完成的,因此需要控制复制源的记录,以便更新被视为更新,而不是写入新的行,即使这些行替换了现有的行。
该选项默认启用;换言之,更新默认被视为写入。也就是说,更新默认被写入为 write_row 事件,而不是 update_row 事件。
要禁用该选项,请使用 --ndb-log-update-as-write=0 或 --ndb-log-update-as-write=OFF 启动源 mysqld。您必须在从 NDB 表复制到使用不同存储引擎的表时这样做;请参阅 从 NDB 复制到其他存储引擎 和 从 NDB 复制到非事务性存储引擎,以获取更多信息。
Important
对于使用 NDB$MAX_INS() 或 NDB$MAX_DEL_WIN_INS() 的插入冲突解决,SQL 节点(即 mysqld 进程)可以记录源集群上的行更新为 WRITE_ROW 事件,以便 idempotency 和最优大小。这对于这些算法有效,因为它们都将 WRITE_ROW 事件映射到插入或更新,具体取决于行是否已经存在,并且所需的元数据(时间戳列的“after”图像)存在于 WRITE_ROW 事件中。